
Ryan Isbell | September 20, 2018
Despite many years of version control maturity, it remains an intimidating tool for many at a conceptual level. But its utility, efficiency, and applications far outweigh any cost it might incur. Easily automated backups, infinite potential to restore old or overwritten code, and of course unparalleled convenience in parallelized coding make it a must-have tool for the professional developer. Git in particular provides a level of flexibility that is worth exploring for individual developers, teams, and organizations of any scale.
Even in 2018, 13 years since the inception of git and three decades since the first availability of version control software, far too many people are unaware of or intimidated by version control.
Version control provides value in many ways, but one that is oft overlooked is the enabling of fearless development. When a project is version controlled well, it is almost effortless to save the current version, hack away at it without fear, and simply roll it back in the event that a mistake is made, or an experiment goes awry. This is the best case for single-user version control. The time invested in setting up version control and learning how to use it is quickly paid for by the time saved in correcting mistakes, actually changing code instead of analyzing risk, and recovering from failed experiments.
The second case for single-user version control is easy backups and easy portability. Once your version control configuration is in place, meaning you have chosen any and all locations to host your project, it is very quick to save it to all of those locations at once. Its almost as easy to pull it to a completely new location. The users have no need to remember all the places to back up their work, no fear of being too lazy or tired to back things up properly, the version control tool uses the same configuration every time to keep everything consistent. Consider all the data you synchronize between your devices: Calendars, emails, playlists, imagine trying to sync those by hand, one file at a time. Automation that we take for granted is this form of version control.
In multi-user environments, the usefulness of version control naturally becomes more obvious. Individual users can create their own branches of the master copy, keeping them local for small experiments and backing them up to any number of remote sites per their discretion. If they are interrupted, perhaps due to being notified of a required emergency bugfix, they can quickly stash their code without committing it anywhere, work on the emergency, and then seamlessly resume their work on the stashed changes. Best of all, modern version control tools intelligently merge these disparate sets of changes together when they are ready to go back into the master branch, and provide many tools and options in the event that a merge cant be done automatically. These tools demand some learning and research to be used adeptly, but averting a crisis of lost code, backups, or overwrites is worth far more than the single day of attentive learning required to understand even rather complex tools such as git, Mercurial, or Perforce.
For the purposes of demonstration, let‘s focus on git, the most popular and arguably most powerful version control tool.
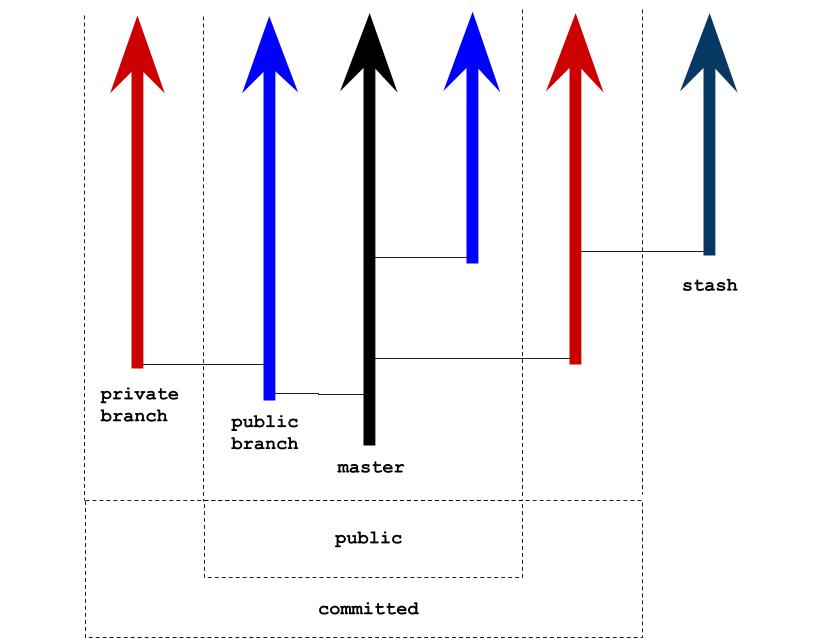
As shown below, the git model (and most version control models) is largely centered around the concept of branching. Customarily there is a master branch, although this is not enforced in git (though it is in other systems). Git is a truly decentralized and distributed system, so there can be as many or few authoritative branches and servers as administrators may desire. And branches may be made publicly or only privately available, which allows any git user to organize their own work however they choose and publish it however they choose. Users additionally have the ability to either commit their changes, saving them permanently in version control, or stash them, which saves them in a private location, effectively setting the work aside temporarily so it can seamlessly be resumed later without interfering with more immediate concerns.
But in order to understand branching effectively, one must first understand exactly what a commit is. It can generally be thought of as saving your progress, just like saving a file, but its much more than that. A commit looks back at the previous commit, and saves the steps that were taken to achieve the new state. So it doesnt save the current state of the project as much as it saves the steps that you took to change it to the current state. The reason this is useful is obvious if you compare it to a command buffer. Most editors of any variety (text, graphics, spreadsheets) have Undo and Redo buttons, which are driven by command buffers. The command buffer remembers what actions you performed in the editor, and lets you step backwards and forwards through them at will. Version control enables the same thing, just at a higher level, delimited by user-defined commits rather than editor-defined commands.
Branching, if it existed in editors, would be the ability to split a command buffer arbitrarily. The Undo tool is often used to step back and try something slightly different, comparing two options. But after Undoing and performing a new action, it isn’t possible to Redo the original action. The action must be performed again manually for comparison. But wouldn’t it be useful if you had the option to choose between Redo-1 and Redo-2? What about Redo-N? This is just one application of branching!
The next obvious useful thing would be management of all of these buffers. Perhaps you build some changes off Redo-1 and other changes off Redo-2, but it turns out you like both of them and would like to combine them. You could manually repeat the work you did in Redo-2 on the path of Redo-1, but why bother when Redo-2 stores all the steps you took anyway? Merging branches plays the recorded changes of one branch onto another. So long as none of the changes contradict each other, this is done cleanly and automatically. If there are contradictions, you simply need to choose which branch’s changes to use, either as a sweeping policy or on a case-by-case basis. The resulting changes are themselves saved as a new commit, since a merge is itself a command you might want to undo, but now you have Undo-1 and Undo-2, depending on whether you’d like to step back into the original Redo-1 path or the Redo-2 path.
The figure below represents a simple branch (experiment) that has been merged (into master), each C(N) is a commit with N representing the order the commit was created. A branch just points to a single specific commit, it doesn’t actually serve any technical purpose other than as a convenient label (which means that anything you do with branches, you could also do directly with commits by their ID). The arrows between commits show how a user may traverse history. They point backwards, but this simply indicates what the commit compares itself to in order to generate the set of changes that it represents.
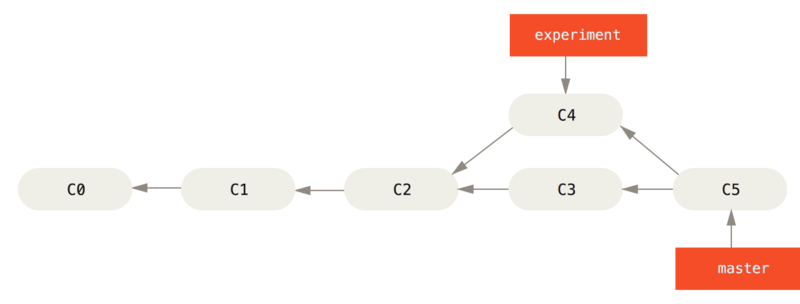
https://git-scm.com/book/en/v2/Git-Branching-Rebasing
Recall that commits and branches can be published and shared, or kept private and local. This means that entire teams of people can be dedicated to working on Redo-1, Redo-2, Redo-N. Tools like git scale beautifully, enabling a single person to work more effectively with their turbocharged Undo/Redo buttons, or enabling complex products to be developed in multiple directions without risk of damaging the original product or of teams interfering with each other’s productivity. Anyone can make their own copy of a public branch, do their own work on it (creating their own private branches if they desire), and then publish their work without worrying about damaging anything. Individuals are responsible for merging their work with any changes that occur on the public branch between their copy (pull) and publish (push). At worst, the public branch can be rolled back to any prior commit as an emergency measure. A public branch might represent a minor product feature, a new release candidate, an emergency hotfix, the master product, or even an experimental path that may be thrown away. Because this is all decentralized, copies of these branches may exist in any number of places, even configured to automatically update each other as changes are received. There is no more resilient way to preserve work than a strongly constructed distributed version control system.
When these concepts are understood at a high level, many more uses of version control become available.
Our best advice: go get git, learn it today, and start using it tomorrow.
References: